When Better Means Worse
I applied class weighting to a 113-category text classifier. Accuracy dropped five points. Macro F1 improved. Ten classes that the model had never once predicted correctly started getting nonzero F1.
My stakeholder would see the accuracy number and ask what I broke.
The numbers
Same model (ModernBERT-base), same data (58K consumer complaints), same everything except a weight tensor on the loss function. Sqrt-inverse weighting — the rarest class gets 3.6x the gradient contribution of the most common.
| Accuracy | Macro F1 | Zero-F1 classes | |
|---|---|---|---|
| Unweighted | 55.4% | 0.199 | 49 |
| Class-weighted | 50.2% | 0.216 | 39 |
For context: the majority-class baseline gets 23% accuracy. TF-IDF with logistic regression gets 54.2%. So the unweighted model is barely above a bag-of-words, and the weighted model dropped below it on accuracy. Both are well above random. Neither is good.
What happened class by class
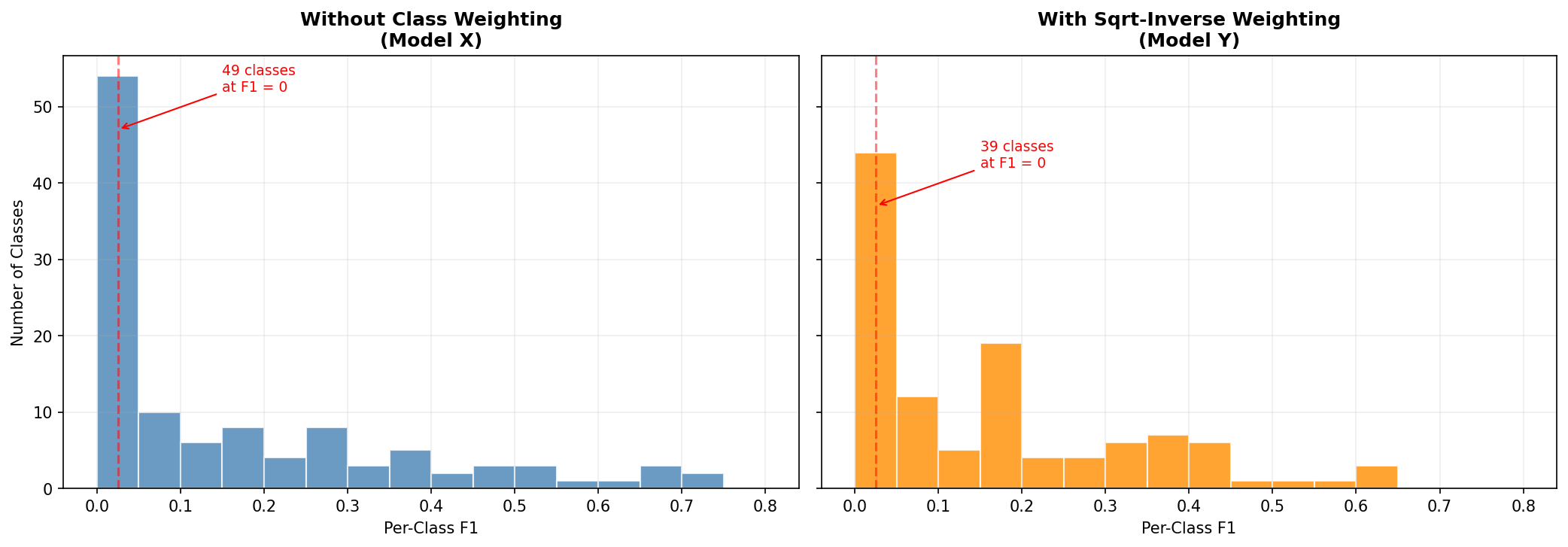
Without weighting, the per-class F1 distribution has a massive spike at zero — 49 classes the model never predicts — and a cluster of head classes between 0.5 and 0.7. With weighting, the zero spike shrinks. The head classes drop a few points each. New bars appear in the 0.1–0.3 range.
The model spent mistakes on common classes to buy predictions on rare ones. Whether that’s an improvement depends on who’s asking. If you route complaints and 80% of volume comes from six categories, you just made your main pipeline worse. If regulators audit whether you can identify all 113 complaint types, you just closed 10 coverage gaps.
The objectives are not aligned
Accuracy asks: what fraction of examples did you get right? Since 23% of examples come from a single class, accuracy rewards getting that class right. Macro F1 asks: what’s the average F1 across all 113 classes? A class with 4 training examples counts the same as a class with 13,000.
Menon et al. showed in 2021 (“Long-Tail Learning via Logit Adjustment”) that the optimal classifier for balanced error and the optimal classifier for accuracy have different decision boundaries. Once you’re trading along that frontier, improving one metric generally comes at the expense of the other. This is not a bug in the training procedure. It is a consequence of the objectives being structurally misaligned.
Macro F1 has its own problems. Noise in the smallest classes can disproportionately move the score — a single validation example flipping changes a class’s F1 from 0.0 to 1.0 or back. But at least it forces you to notice the 49 classes you’re ignoring.
The part nobody wants to talk about
Most organizations claim to care about all classes. The mission statement says so. The product brief says so. But the dashboard tracks aggregate accuracy or top-line error rate, and that’s what gets reported up. Teams are implicitly rewarded for making the big number go up, which means implicitly rewarded for ignoring the tail. The incentive system quietly kills minority-class performance and nobody notices because the metric they watch doesn’t show it.
Class weighting makes this tradeoff visible. That’s why it feels uncomfortable. You’re not discovering a problem. You’re losing the ability to pretend it isn’t there.
So what do you do
You pick. Not “which metric is right” — that question has no answer. You pick which errors your system can tolerate. Then you optimize for that, report the other metric honestly, and make sure the person setting priorities understands what they’re trading away.
The optimizer did what I told it to do both times. I was the one pretending those objectives would point in the same direction.